
Nouvelles sur l'IA du site LinuxFR
Lien vers la série d'article : https://linuxfr.org/tags/nouvelles_sur_l_ia/public
- #JaiLu :
- Nouvelles sur l’IA de février 2025
- Nouvelles sur l’IA de mars 2025
- Nouvelles sur l’IA d’avril 2025
- Nouvelles sur l’IA de mai 2025
- Nouvelles sur l’IA de juin 2025
- Nouvelles sur l’IA de juillet 2025
- Nouvelles sur l’IA d'août 2025
- Nouvelles sur l’IA de septembre 2025
- Nouvelles sur l’IA de octobre 2025
- Nouvelles sur l’IA de novembre 2025
- Nouvelles sur l’IA de décembre 2025
- Nouvelles sur l’IA de février 2026
- Nouvelles sur l’IA de mars 2026
Voir aussi le TIL de Simon Willison.
Journaux liées à cette note :
Comment je me renseigne sur un nouveau modèle LLM en 4 étapes
Voici le process que je suis lorsque je découvre un nouveau modèle LLM et que je souhaite en savoir plus à son propos.
Étape 1 : blog de Simon Willison
Je commence par jeter un œil rapide sur le blog de Simon Willison, car cela fait plusieurs années que je le suis et j'apprécie son expertise et ses analyses de modèles.
Étape 2 : les articles de Artificial Analysis
Ensuite je regarde les articles (https://artificialanalysis.ai/articles) d'Artificial Analysis, pour voir s'ils ont publié un nouvel article sur ce modèle. Généralement, ils sont très réactifs. Voici un exemple concernant Kimi K2.6 : Kimi K2.6: The new leading open weights model.
J'aime beaucoup la structure de leurs articles.
Tout d'abord, une section synthétique avec des informations majeures du modèle :

Ensuite, la position du nouveau modèle pour différents leaderboards :
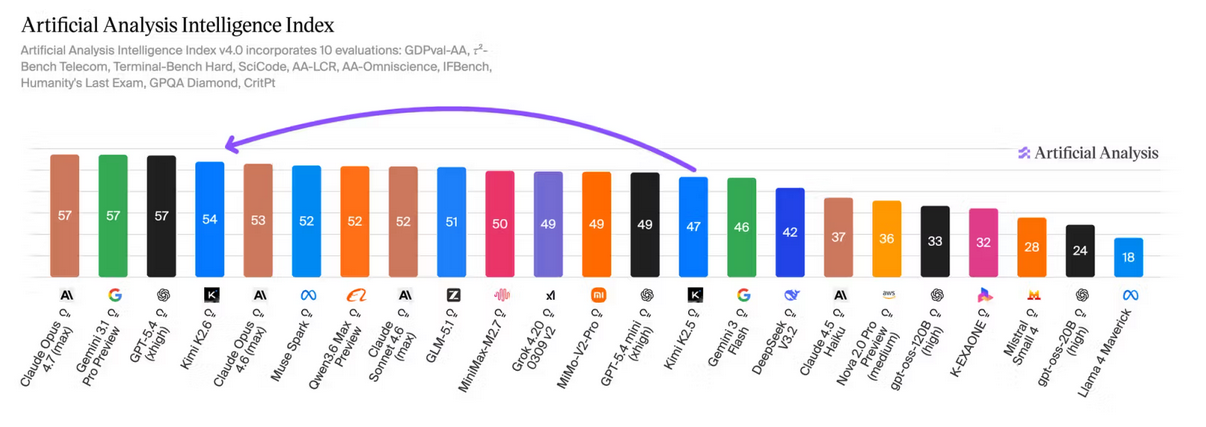
Étape 3 : Analyse des commentaires HackerNews
En troisième étape, j'utilise le moteur de recherche de Hacker News pour identifier le thread qui traite du modèle. Voici par exemple celui à propos de Kimi K2.6: Advancing open-source coding et ses 371 commentaires.
À partir de l'url de ce thread, je lance le prompt suivant dans Claude Desktop connecté au serveur MCP fetch lancé localement :
Utilise `fetch_html` pour récupérer https://news.ycombinator.com/item?id=47835735
**Étape 1 — Récupération complète**
- Récupère la première page avec `fetch_html` et lis le nombre total de commentaires indiqué en début de page — ce nombre est ta cible obligatoire
- Le contenu étant probablement tronqué (limite 200 000 caractères), enchaîne les appels successifs en incrémentant `start_index` de 200 000 à chaque fois :
- `fetch_html(url, start_index=0, max_length=200000)`
- `fetch_html(url, start_index=200000, max_length=200000)`
- `fetch_html(url, start_index=400000, max_length=200000)`
- … jusqu'à ce que la réponse soit vide
- **Tu dois avoir récupéré 100% des commentaires avant de passer à l'étape suivante.** Vérifie que le nombre de commentaires extraits correspond au compteur initial — si ce n'est pas le cas, continue à paginer.
**Étape 2 — Analyse exhaustive**
Analyse **chacun des commentaires sans exception** exclusivement sous l'angle des **modèles LLM** mentionnés. Aucun commentaire ne doit être ignoré ou échantillonné.
Pour chaque modèle cité, synthétise :
- **Points forts** relevés par les commentateurs
- **Points faibles** ou limitations mentionnées
- **Cas d'usage Coding** : performance en génération de code, débogage, complétion, etc.
- **Cas d'usage Intelligence générale** : raisonnement, compréhension, tâches polyvalentes, etc.
- **Benchmarks mentionnés** : scores, classements ou comparaisons chiffrées associés à ce modèle
**Étape 3 — Synthèse**
Présente le résultat sous forme de **deux tableaux comparatifs markdown** :
1. **Tableau Coding** — colonnes : Modèle | Points forts | Points faibles | Benchmarks coding
2. **Tableau Intelligence générale** — colonnes : Modèle | Points forts | Points faibles | Benchmarks généralistes
Puis ajoute :
1. Une section **"Comparaison directe entre modèles"** synthétisant les confrontations explicites faites par les commentateurs (quel modèle bat quel autre, sur quoi, dans quel contexte), en distinguant coding vs intelligence générale
2. Une section **"Benchmarks en discussion"** listant les benchmarks cités, leur crédibilité perçue par la communauté, et les modèles qu'ils avantagent ou désavantagent — en précisant s'il s'agit de benchmarks coding (HumanEval, SWE-bench…) ou généralistes (MMLU, GPQA…)
Seuls les commentaires sans aucune mention de modèle spécifique sont à ignorer.
Ce qui m'a donné le résultat suivant : Analyse par Sonnet 4.6 des commentaires Hacker News à propos de Kimi K2.6.
Étape 4 : quelques semaines plus tard
Quelques semaines plus tard, je consulte toutes les sorties de modèle du mois dans l'article Nouvelles sur l'IA du site LinuxFR pour avoir une revue complète de l'écosystème.
Journal du dimanche 22 juin 2025 à 15:02
Je viens de découvrir les quatre premiers articles de la série "Nouvelle sur l'IA" sur LinuxFr :
- Nouvelles sur l’IA de février 2025
- Nouvelles sur l’IA de mars 2025
- Nouvelles sur l’IA d’avril 2025
- Nouvelles sur l’IA de mai 2025
L'auteur de ces articles indique en introduction :
Avertissement : presque aucun travail de recherche de ma part, je vais me contenter de faire un travail de sélection et de résumé sur le contenu hebdomadaire de Zvi Mowshowitz.
Je viens d'ajouter ces deux feed à ma note "Mes sources de veille en IA".
Prise de note de lecture de : Nouvelles sur l’IA de février 2025
Je découvre la signification de l'acronyme STEM : Science, technology, engineering, and mathematics.
Une procédure standard lors de la divulgation d’un nouveau modèle (chez OpenAI en tout cas) est de présenter une "System Card", aka "à quel point notre modèle est dangereux ou inoffensif".
#JaiDécouvert le concept de System Card, concept qui semble avoir été introduit par Meta en février 2022 : « System Cards, a new resource for understanding how AI systems work » (je n'ai pas lu l'article).
#JaiDécouvert ChatGPT Deep Research.
Je retiens :
Derya Unutmaz, MD: J'ai demandé à Deep Researchh de m'aider sur deux cas de cancer plus tôt aujourd'hui. L'un était dans mon domaine d'expertise et l'autre légèrement en dehors. Les deux rapports étaient tout simplement impeccables, comme quelque chose que seul un médecin spécialiste pourrait écrire ! Il y a une raison pour laquelle j'ai dit que c'est un changement radical ! 🤯
Et
Je suis quelque peu déçu par Deep Research d'@OpenAI. @sama avait promis que c'était une avancée spectaculaire, alors j'y ai entré la plainte pour notre procès guidé par o1 contre @DCGco et d'autres, et lui ai demandé de prendre le rôle de Barry Silbert et de demander le rejet de l'affaire.
Malheureusement, bien que le modèle semble incroyablement intelligent, il a produit des arguments manifestement faibles car il a fini par utiliser des données sources de mauvaise qualité provenant de sites web médiocres. Il s'est appuyé sur des sources comme Reddit et ces articles résumés que les avocats écrivent pour générer du trafic vers leurs sites web et obtenir de nouveaux dossiers.
Les arguments pour le rejet étaient précis dans le contexte des sites web sur lesquels il s'est appuyé, mais après examen, j'ai constaté que ces sites simplifient souvent excessivement la loi et manquent des points essentiels des textes juridiques réels.
#JaiDécouvert qu'il est possible de configurer la durée de raisonnement de Clause Sonnet 3.7 :
Aujourd'hui, nous annonçons Claude Sonnet 3.7, notre modèle le plus intelligent à ce jour et le premier modèle de raisonnement hybride sur le marché. Claude 3.7 Sonnet peut produire des réponses quasi instantanées ou une réflexion approfondie, étape par étape, qui est rendue visible à l'utilisateur. Les utilisateurs de l'API ont également un contrôle précis sur la durée de réflexion accordée au modèle.
#JaiDécouvert que l'offre LLM par API de Google se nomme Vertex AI.
#JaiDécouvert que les System Prompt d'Anthropic sont publics : https://docs.anthropic.com/en/release-notes/system-prompts#feb-24th-2025
J'ai trouvé la section "Gradual Disempowerement" très intéressante. #JaimeraisUnJour prendre le temps de faire une lecture active de l'article : Gradual Disempowerment.
Je viens de consacrer 1h30 de lecture active de l'article de février 2025. Je le recommande fortement pour ceux qui s'intéressent au sujet. Merci énormément à son auteur Moonz.
Je vais publier cette note et ensuite commencer la lecture de l'article de mars 2025.